Publications
2025
-
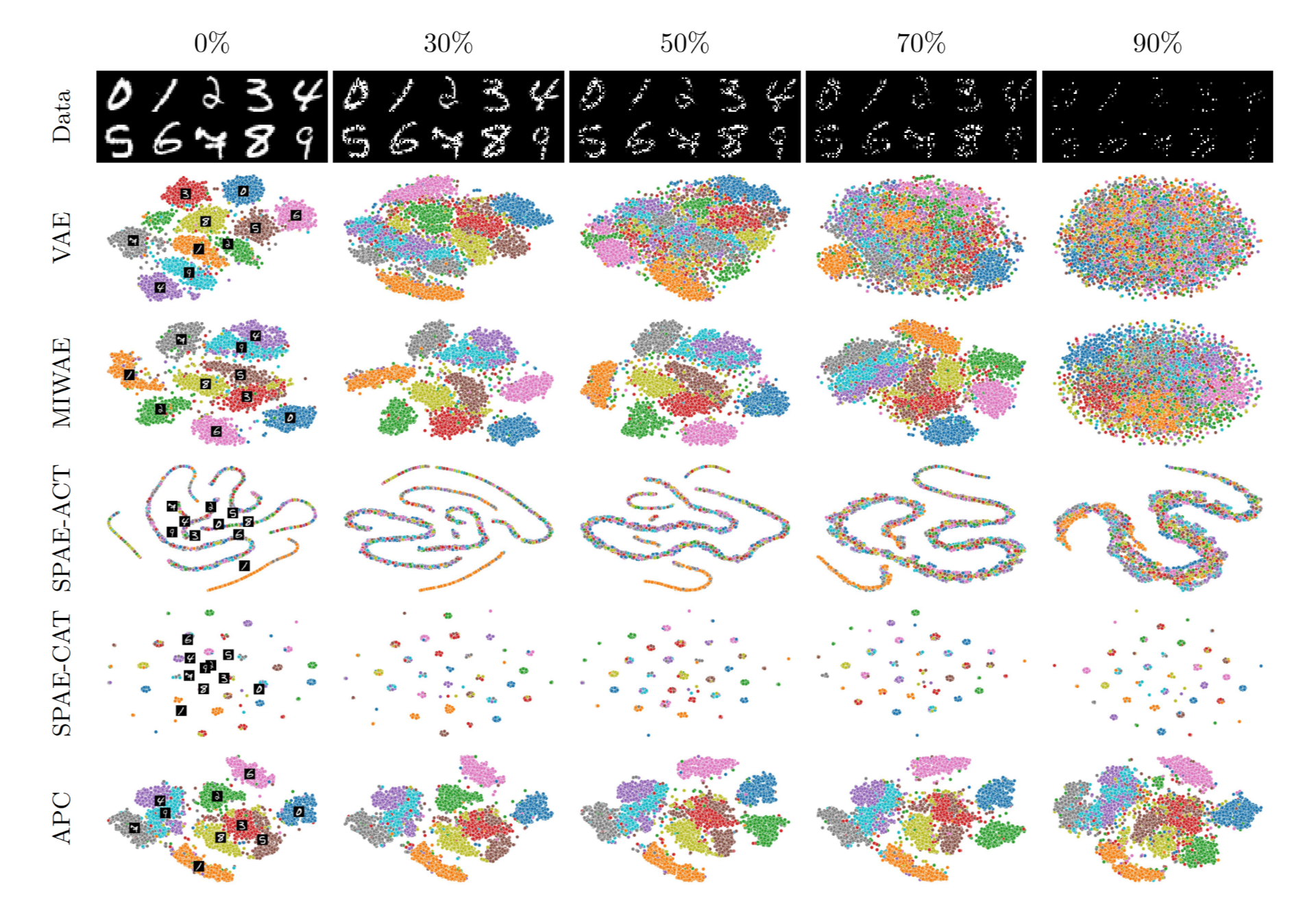 Tractable Representation Learning with Probabilistic CircuitsSteven Braun, Sahil Sidheekh, Antonio Vergari, Martin Mundt, Sriraam Natarajan, and Kristian KerstingTransactions on Machine Learning Research, 2025
Tractable Representation Learning with Probabilistic CircuitsSteven Braun, Sahil Sidheekh, Antonio Vergari, Martin Mundt, Sriraam Natarajan, and Kristian KerstingTransactions on Machine Learning Research, 2025Probabilistic circuits (PCs) are powerful probabilistic models that enable exact and tractable inference, making them highly suitable for probabilistic reasoning and inference tasks. While dominant in neural networks, representation learning with PCs remains underexplored, with prior approaches relying on external neural embeddings or activation-based encodings. To address this gap, we introduce autoencoding probabilistic circuits (APCs), a novel framework leveraging the tractability of PCs to model probabilistic embeddings explicitly. APCs extend PCs by jointly modeling data and embeddings, obtaining embedding representations through tractable probabilistic inference. The PC encoder allows the framework to natively handle arbitrary missing data and is seamlessly integrated with a neural decoder in a hybrid, end-to-end trainable architecture enabled by differentiable sampling. Our empirical evaluation demonstrates that APCs outperform existing PC-based autoencoding methods in reconstruction quality, generate embeddings competitive with, and exhibit superior robustness in handling missing data compared to neural autoencoders. These results highlight APCs as a powerful and flexible representation learning method that exploits the probabilistic inference capabilities of PCs, showing promising directions for robust inference, out-of-distribution detection, and knowledge distillation.
@article{braun2025apcs, title = {Tractable Representation Learning with Probabilistic Circuits}, author = {Braun, Steven and Sidheekh, Sahil and Vergari, Antonio and Mundt, Martin and Natarajan, Sriraam and Kersting, Kristian}, year = {2025}, journal = {Transactions on Machine Learning Research}, bibtext_show = {true} }

2024
-
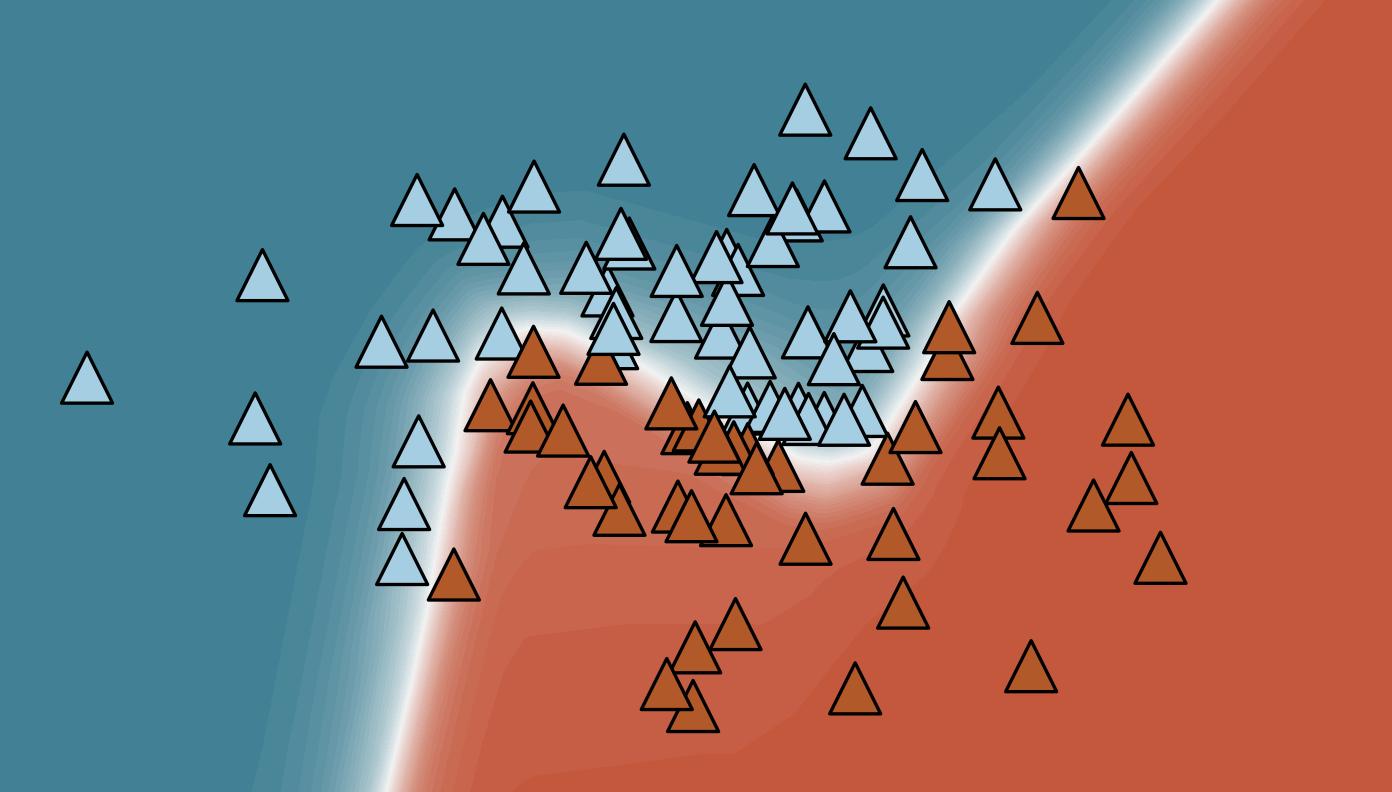 Deep Classifier Mimicry without Data AccessSteven Braun, Martin Mundt, and Kristian KerstingInternational Conference on Artificial Intelligence and Statistics (AISTATS) – Oral & Student Paper Highlight Award, 2024
Deep Classifier Mimicry without Data AccessSteven Braun, Martin Mundt, and Kristian KerstingInternational Conference on Artificial Intelligence and Statistics (AISTATS) – Oral & Student Paper Highlight Award, 2024Access to pre-trained models has recently emerged as a standard across numerous machine learning domains. Unfortunately, access to the original data the models were trained on may not equally be granted. This makes it tremendously challenging to fine-tune, compress models, adapt continually, or to do any other type of data-driven update. We posit that original data access may however not be required. Specifically, we propose Contrastive Abductive Knowledge Extraction (CAKE), a model-agnostic knowledge distillation procedure that mimics deep classifiers without access to the original data. To this end, CAKE generates pairs of noisy synthetic samples and diffuses them contrastively toward a model’s decision boundary. We empirically corroborate CAKE’s effectiveness using several benchmark datasets and various architectural choices, paving the way for broad application.

2023
-
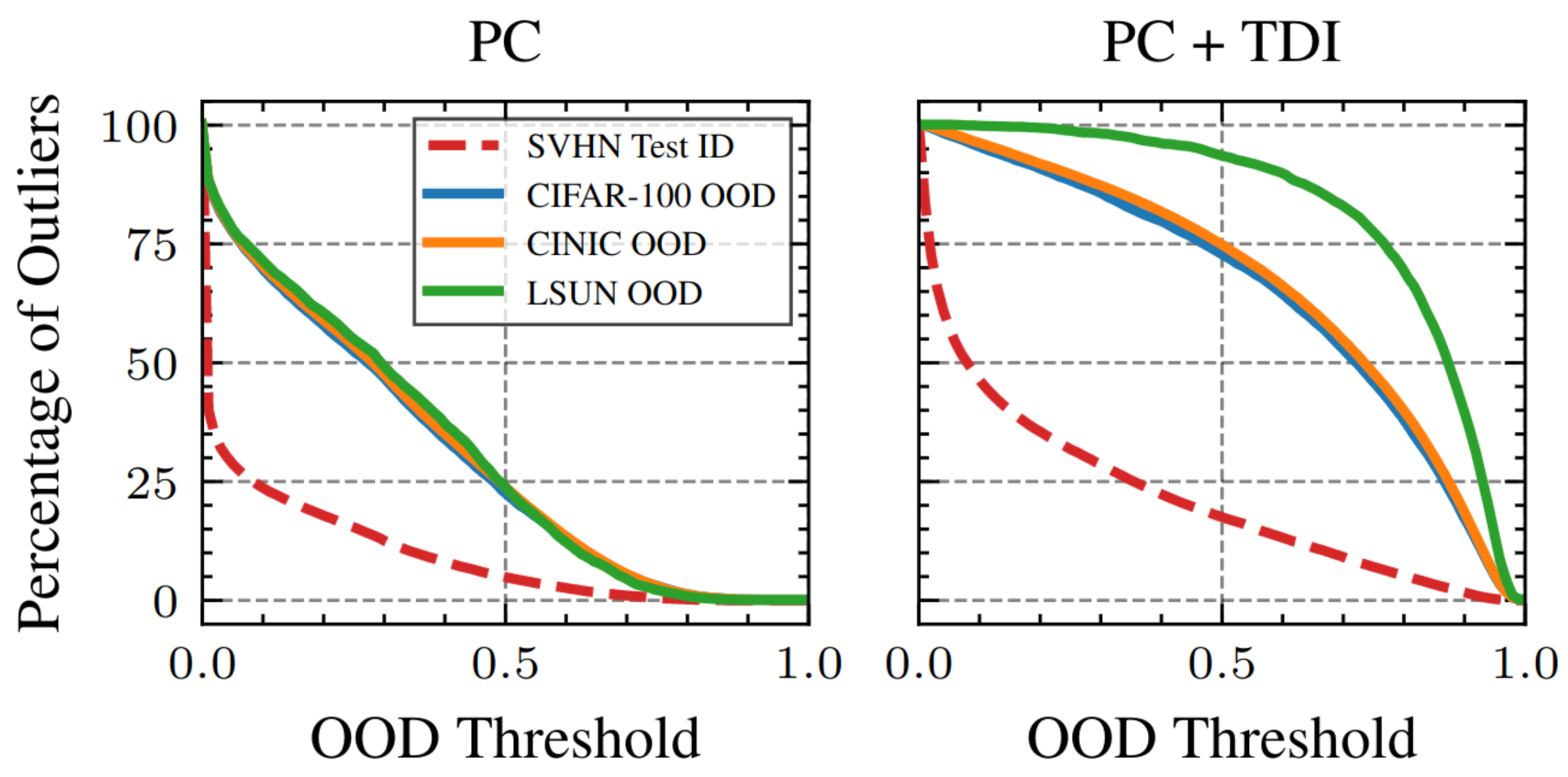 Probabilistic Circuits That Know What They Don’t KnowFabrizio Ventola*, Steven Braun*, Zhongjie Yu, Martin Mundt, and Kristian KerstingProceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI), 2023
Probabilistic Circuits That Know What They Don’t KnowFabrizio Ventola*, Steven Braun*, Zhongjie Yu, Martin Mundt, and Kristian KerstingProceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI), 2023Probabilistic circuits (PCs) are models that allow exact and tractable probabilistic inference. In contrast to neural networks, they are often assumed to be well-calibrated and robust to out-of-distribution (OOD) data. In this paper, we show that PCs are in fact not robust to OOD data, i.e., they don’t know what they don’t know. We then show how this challenge can be overcome by model uncertainty quantification. To this end, we propose tractable dropout inference (TDI), an inference procedure to estimate uncertainty by deriving an analytical solution to Monte Carlo dropout (MCD) through variance propagation. Unlike MCD in neural networks, which comes at the cost of multiple network evaluations, TDI provides tractable sampling-free uncertainty estimates in a single forward pass. TDI improves the robustness of PCs to distribution shift and OOD data, demonstrated through a series of experiments evaluating the classification confidence and uncertainty estimates on real-world data.
@article{braun2023tdi, author = {Ventola*, Fabrizio and Braun*, Steven and Yu, Zhongjie and Mundt, Martin and Kersting, Kristian}, title = {Probabilistic Circuits That Know What They Don't Know}, year = {2023}, journal = {Proceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI)} }

2022
-
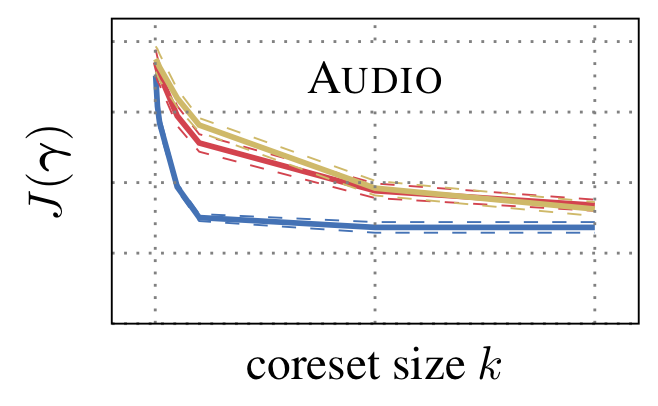 Towards Coreset Learning in Probabilistic CircuitsMartin Trapp, Steven Lang, Aastha Shah, Martin Mundt, Kristian Kersting, and Arno SolinIn The 5th Workshop on Tractable Probabilistic Modeling (UAI), 2022
Towards Coreset Learning in Probabilistic CircuitsMartin Trapp, Steven Lang, Aastha Shah, Martin Mundt, Kristian Kersting, and Arno SolinIn The 5th Workshop on Tractable Probabilistic Modeling (UAI), 2022Probabilistic circuits (PCs) are a powerful family of tractable probabilistic models, guaranteeing efficient and exact computation of many probabilistic inference queries. However, their sparsely structured nature makes computations on large data sets challenging to perform. Recent works have focused on tensorized representations of PCs to speed up computations on large data sets. In this work, we present an orthogonal approach by sparsifying the set of n observations and show that finding a coreset of k≪n data points can be phrased as a monotone submodular optimisation problem which can be solved greedily for a deterministic PCs of |\G| nodes in \mathcalO(k \,n |\G|). Finally, we verify on a series of data sets that our greedy algorithm outperforms random selection.
@inproceedings{trapp2022towards, title = {Towards Coreset Learning in Probabilistic Circuits}, author = {Trapp, Martin and Lang, Steven and Shah, Aastha and Mundt, Martin and Kersting, Kristian and Solin, Arno}, booktitle = {The 5th Workshop on Tractable Probabilistic Modeling (UAI)}, year = {2022}, } -
 CLEVA-Compass: A Continual Learning EValuation Assessment Compass to Promote Research Transparency and ComparabilityMartin Mundt, Steven Lang, Quentin Delfosse, and Kristian KerstingIn International Conference on Learning Representations (ICLR), 2022
CLEVA-Compass: A Continual Learning EValuation Assessment Compass to Promote Research Transparency and ComparabilityMartin Mundt, Steven Lang, Quentin Delfosse, and Kristian KerstingIn International Conference on Learning Representations (ICLR), 2022What is the state of the art in continual machine learning? Although a natural question for predominant static benchmarks, the notion to train systems in a life- long manner entails a plethora of additional challenges with respect to set-up and evaluation. The latter have recently sparked a growing amount of critiques on prominent algorithm-centric perspectives and evaluation protocols being too nar- row, resulting in several attempts at constructing guidelines in favor of specific desiderata or arguing against the validity of prevalent assumptions. In this work, we depart from this mindset and argue that the goal of a precise formulation of desiderata is an ill-posed one, as diverse applications may always warrant distinct scenarios. Instead, we introduce the Continual Learning EValuation Assessment Compass: the CLEVA-Compass. The compass provides the visual means to both identify how approaches are practically reported and how works can simultane- ously be contextualized in the broader literature landscape. In addition to promot- ing compact specification in the spirit of recent replication trends, it thus provides an intuitive chart to understand the priorities of individual systems, where they resemble each other, and what elements are missing towards a fair comparison.
@inproceedings{mundt2021clevacompass, title = {CLEVA-Compass: A Continual Learning EValuation Assessment Compass to Promote Research Transparency and Comparability}, author = {Mundt, Martin and Lang, Steven and Delfosse, Quentin and Kersting, Kristian}, year = {2022}, booktitle = {International Conference on Learning Representations (ICLR)}, } -
 Elevating Perceptual Sample Quality in Probabilistic Circuits through Differentiable SamplingSteven Lang, Martin Mundt, Fabrizio Ventola, Robert Peharz, and Kristian KerstingIn Proceedings of Machine Learning Research, Workshop on Preregistration in Machine Learning (NeurIPS), 2022
Elevating Perceptual Sample Quality in Probabilistic Circuits through Differentiable SamplingSteven Lang, Martin Mundt, Fabrizio Ventola, Robert Peharz, and Kristian KerstingIn Proceedings of Machine Learning Research, Workshop on Preregistration in Machine Learning (NeurIPS), 2022Deep generative models have seen a dramatic improvement in recent years, due to the use of alternative losses based on perceptual assessment of generated samples. This improvement has not yet been applied to the model class of probabilistic circuits (PCs), presumably due to significant technical challenges concerning differentiable sampling, which is a key requirement for optimizing perceptual losses. This is unfortunate, since PCs allow a much wider range of probabilistic inference routines than main-stream generative models, such as exact and efficient marginalization and conditioning. Motivated by the success of loss reframing in deep generative models, we incorporate perceptual metrics into the PC learning objective. To this aim, we introduce a differentiable sampling procedure for PCs, where the central challenge is the non-differentiability of sampling from the categorical distribution over latent PC variables. We take advantage of the Gumbel-Softmax trick and develop a novel inference pass to smoothly interpolate child samples as a strategy to circumvent non-differentiability of sum node sampling. We initially hypothesized, that perceptual losses, unlocked by our novel differentiable sampling procedure, will elevate the generative power of PCs and improve their sample quality to be on par with neural counterparts like probabilistic auto-encoders and generative adversarial networks. Although our experimental findings empirically reject this hypothesis for now, the results demonstrate that samples drawn from PCs optimized with perceptual losses can have similar sample quality compared to likelihood-based optimized PCs and, at the same time, can express richer contrast, colors, and details. Whereas before, PCs were restricted to likelihood-based optimization, this work has paved the way to advance PCs with loss formulations that have been built around deep neural networks in recent years.
@inproceedings{lang2022diff-sampling-spns, title = {Elevating Perceptual Sample Quality in Probabilistic Circuits through Differentiable Sampling}, author = {Lang, Steven and Mundt, Martin and Ventola, Fabrizio and Peharz, Robert and Kersting, Kristian}, booktitle = {Proceedings of Machine Learning Research, Workshop on Preregistration in Machine Learning (NeurIPS)}, keywords = {Probabilistic Circuits, Sum-Product Networks, Differentiable Sampling, Deep Learning}, year = {2022}, volume = {181}, series = {Proceedings of Machine Learning Research}, pages = {1--25}, publisher = {PMLR}, }



2021
-
 DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object DetectionSteven Lang, Fabrizio Ventola, and Kristian KerstingarXiv preprint, arXiv:2109.06148, 2021
DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object DetectionSteven Lang, Fabrizio Ventola, and Kristian KerstingarXiv preprint, arXiv:2109.06148, 2021We present DAFNe, a Dense one-stage Anchor-Free deep Network for oriented object detection. As a one-stage model, it performs bounding box predictions on a dense grid over the input image, being architecturally simpler in design, as well as easier to optimize than its two-stage counterparts. Furthermore, as an anchor-free model, it reduces the prediction complexity by refraining from employing bounding box anchors. With DAFNe we introduce an orientation-aware generalization of the center-ness function for arbitrarily oriented bounding boxes to down-weight low-quality predictions and a center-to-corner bounding box prediction strategy that improves object localization performance. Our experiments show that DAFNe outperforms all previous one-stage anchor-free models on DOTA 1.0, DOTA 1.5, and UCAS-AOD and is on par with the best models on HRSC2016.
@article{lang2021dafne, title = {DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object Detection}, author = {Lang, Steven and Ventola, Fabrizio and Kersting, Kristian}, year = {2021}, eprint = {2109.06148}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, journal = {arXiv preprint, arXiv:2109.06148}, }

2020
-
 Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic CircuitsRobert Peharz, Steven Lang, Antonio Vergari, Karl Stelzner, Alejandro Molina, Martin Trapp, Guy Van Den Broeck, Kristian Kersting, and Zoubin GhahramaniIn Proceedings of the 37th International Conference on Machine Learning (ICML), 2020
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic CircuitsRobert Peharz, Steven Lang, Antonio Vergari, Karl Stelzner, Alejandro Molina, Martin Trapp, Guy Van Den Broeck, Kristian Kersting, and Zoubin GhahramaniIn Proceedings of the 37th International Conference on Machine Learning (ICML), 2020Probabilistic circuits (PCs) are a promising av- enue for probabilistic modeling, as they permit a wide range of exact and efficient inference rou- tines. Recent “deep-learning-style” implementa- tions of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation- Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Further- more, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.
@inproceedings{pmlr-v119-peharz20a, title = {Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits}, author = {Peharz, Robert and Lang, Steven and Vergari, Antonio and Stelzner, Karl and Molina, Alejandro and Trapp, Martin and Van Den Broeck, Guy and Kersting, Kristian and Ghahramani, Zoubin}, booktitle = {Proceedings of the 37th International Conference on Machine Learning (ICML)}, pages = {7563--7574}, year = {2020}, editor = {III, Hal Daumé and Singh, Aarti}, volume = {119}, series = {Proceedings of Machine Learning Research}, publisher = {PMLR}, url = {http://proceedings.mlr.press/v119/peharz20a.html}, }

2019
-
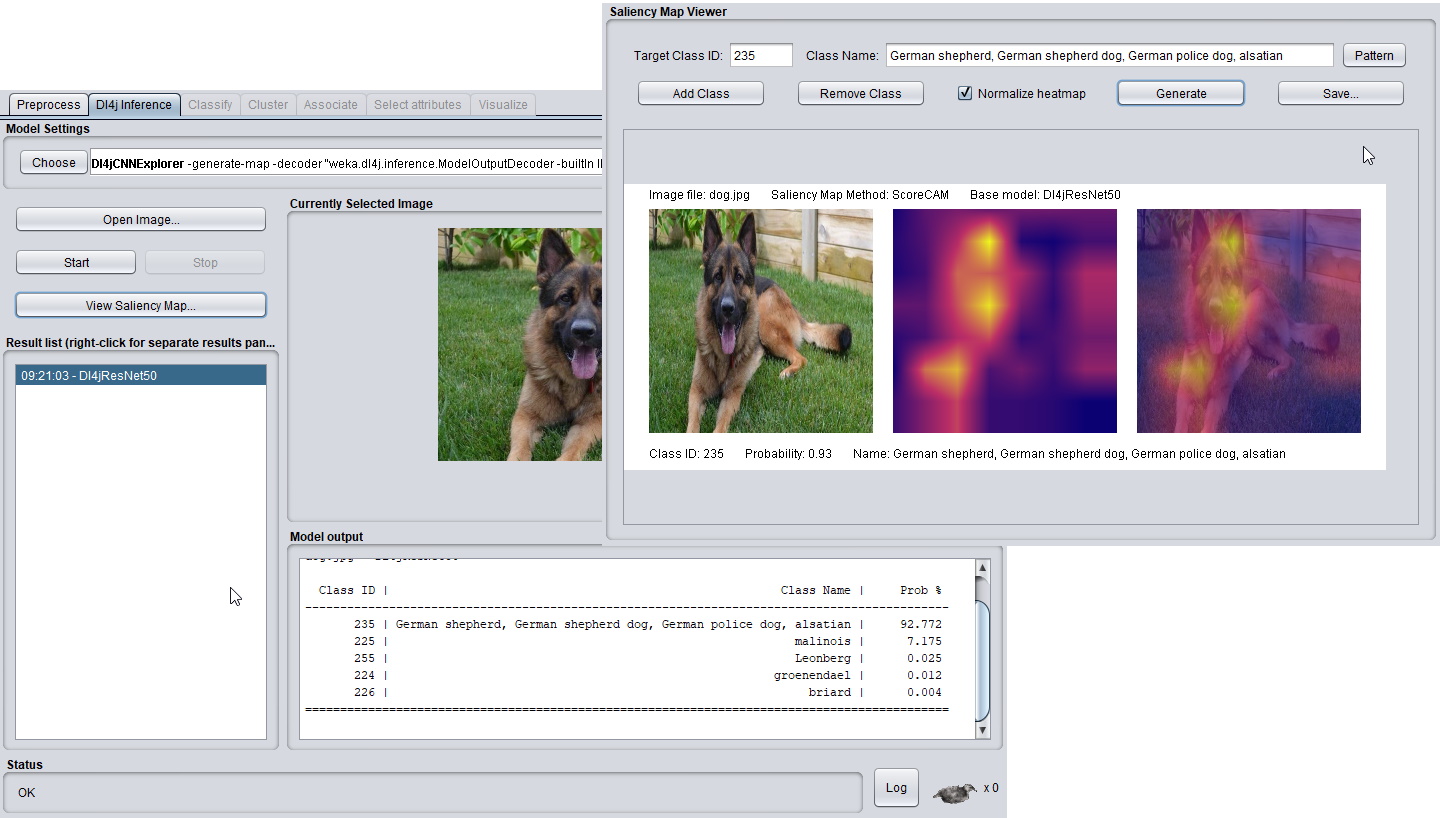 WekaDeeplearning4j: A deep learning package for Weka based on Deeplearning4jSteven Lang, Felipe Bravo-Marquez, Christopher Beckham, Mark Hall, and Eibe FrankKnowledge-Based Systems, 2019
WekaDeeplearning4j: A deep learning package for Weka based on Deeplearning4jSteven Lang, Felipe Bravo-Marquez, Christopher Beckham, Mark Hall, and Eibe FrankKnowledge-Based Systems, 2019Deep learning is a branch of machine learning that generates multi-layered representations of data, commonly using artificial neural networks, and has improved the state-of-the-art in various machine learning tasks (e.g., image classification, object detection, speech recognition, and document classifica- tion). However, most popular deep learning frameworks such as TensorFlow and PyTorch require users to write code to apply deep learning. We present WekaDeeplearning4j, a Weka package that makes deep learning accessible through a graphical user interface (GUI). The package uses Deeplearning4j as its backend, provides GPU support, and enables GUI-based training of deep neural networks such as convolutional and recurrent neural networks. It also provides pre-processing functionality for image and text data.
@article{lang2019wekadeeplearning4j, title = {WekaDeeplearning4j: A deep learning package for Weka based on Deeplearning4j}, author = {Lang, Steven and Bravo-Marquez, Felipe and Beckham, Christopher and Hall, Mark and Frank, Eibe}, journal = {Knowledge-Based Systems}, volume = {178}, pages = {48 - 50}, year = {2019}, issn = {0950-7051}, doi = {https://doi.org/10.1016/j.knosys.2019.04.013}, url = {http://www.sciencedirect.com/science/article/pii/S0950705119301789}, publisher = {Elsevier}, }
